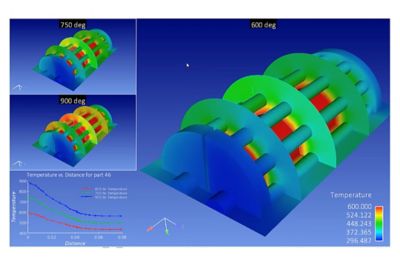



















Quick Specs
EnSight allows you to extract the salient information by providing a powerful set of analysis tools and techniques. From common tools to cutting-edge features such as Volume Rendering and LIC, explore your data visually. Visualize data from more than one design simultaneously, even from different solvers.